
Современные компании при принятии стратегических решений опираются на данные. Для эффективных результатов развития бизнеса крайне важно, чтобы эти данные были полными и качественными. Недостаточно обработанная информация может ввести в заблуждение, что снижает вероятность правильных выводов при анализе, соответственно, принятое решение может оказаться неэффективным или вовсе ухудшить показатели бизнеса.
Для повышения качества данных и их подготовки к визуализации выполняется их обогащение — процесс, который дополняет необработанные данные контекстом, делая их более полезными для бизнес-аналитики и принятия решений.
Предлагаем рассмотреть один из способов обогащения данных — создание различных вычисляемых полей на базе сервиса Analytic Workspace.
В качестве примера возьмем данные, содержащие информацию о самых продаваемых книгах.
Таблица будет содержать следующие поля:
Изучив данные, мы видим, что у нас есть целый ряд строковых полей и 2 числовых. Одно из числовых полей отвечает за год. С этим знанием перейдем к созданию полей.
Для повышения качества данных и их подготовки к визуализации выполняется их обогащение — процесс, который дополняет необработанные данные контекстом, делая их более полезными для бизнес-аналитики и принятия решений.
Предлагаем рассмотреть один из способов обогащения данных — создание различных вычисляемых полей на базе сервиса Analytic Workspace.
В качестве примера возьмем данные, содержащие информацию о самых продаваемых книгах.
Таблица будет содержать следующие поля:
- название книги;
- автор;
- язык публикации;
- год публикации;
- объем продаж (в миллионах);
- жанр.
Изучив данные, мы видим, что у нас есть целый ряд строковых полей и 2 числовых. Одно из числовых полей отвечает за год. С этим знанием перейдем к созданию полей.


Какие вычисляемые поля добавить?
Самый простой вариант — математическая операция.
Возникают ситуации, когда нужно, чтобы новые данные были умножены на некий коэффициент или значение другого поля. В таких случаях в вычисляемое поле без лишних дополнений вписывается то выражение, которое вам необходимо.
Пример: получение результата продаж в единицах из миллионов.
Самый простой вариант — математическая операция.
Возникают ситуации, когда нужно, чтобы новые данные были умножены на некий коэффициент или значение другого поля. В таких случаях в вычисляемое поле без лишних дополнений вписывается то выражение, которое вам необходимо.
Пример: получение результата продаж в единицах из миллионов.


Редакция строк
В вычисляемом поле можно создать выражение, позволяющее форматировать текст внутри поля. Опираясь на наш пример, добавим поле, которое будет оставлять от имени автора только фамилию.
В вычисляемом поле можно создать выражение, позволяющее форматировать текст внутри поля. Опираясь на наш пример, добавим поле, которое будет оставлять от имени автора только фамилию.
Пример:
substr (author_s, instr (author_s, ' '))
Данный запрос состоит из нескольких функций:
instr (author_s, ' ') — возвращает индекс первого встретившегося в строке символа (символ указывается вторым параметром, в данном случае — пробел)
substr (author_s, instr (author_s, ' ')) — возвращает подстроку из строки author_s. Вторым параметром задается номер символа, с которого читаем до конца строки.
instr (author_s, ' ') — возвращает индекс первого встретившегося в строке символа (символ указывается вторым параметром, в данном случае — пробел)
substr (author_s, instr (author_s, ' ')) — возвращает подстроку из строки author_s. Вторым параметром задается номер символа, с которого читаем до конца строки.
Добавление оконной функции
В поле «продажи в миллионах» хранится число продаж по каждой книге. Однако это число «200» характеризует не только конкретную книгу, но и другие важные показатели.
В поле «продажи в миллионах» хранится число продаж по каждой книге. Однако это число «200» характеризует не только конкретную книгу, но и другие важные показатели.

А именно:
Таким образом, с помощью оконных функций мы можем создать агрегацию параметров, и полученный по группе результат записать в соседнем поле числом, при этом не изменяя внешний вид таблицы.
Рассмотрим, как выглядит результат нахождения агрегации с использованием функции group by.
- количество продаж книг от автора Чарльза Дикенса;
- количество книг, написанных в 1859 году;
- количество книг жанра «историческая фантастика».
Таким образом, с помощью оконных функций мы можем создать агрегацию параметров, и полученный по группе результат записать в соседнем поле числом, при этом не изменяя внешний вид таблицы.
Рассмотрим, как выглядит результат нахождения агрегации с использованием функции group by.
select author_s, sum(approximate_sales_in_millions)
from child
group by author_s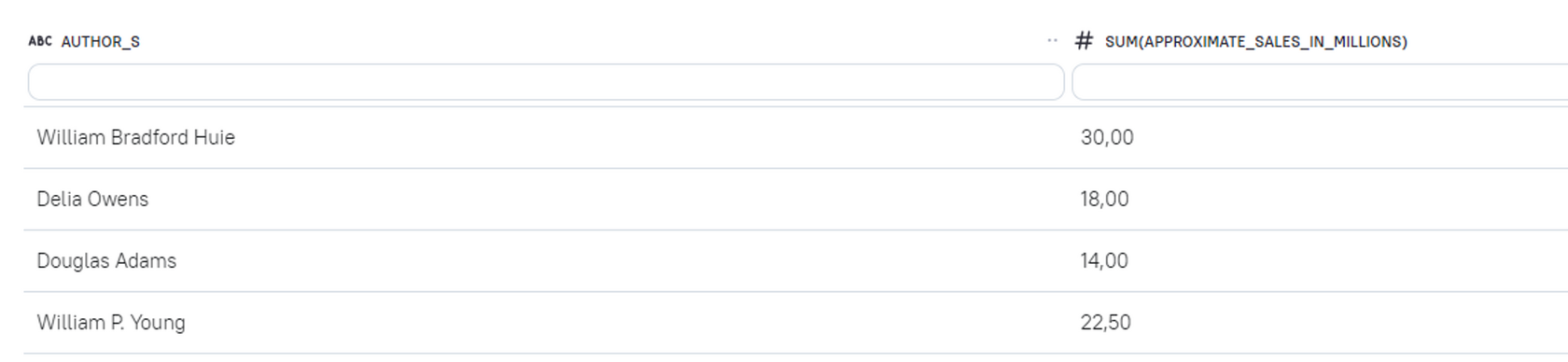
group by не позволяет добавлять в таблицу поля без агрегирующей функции. Поля, которые невозможно агрегировать — например, название книги — теряются. При использовании оконных функций потерь не происходит, и в этом их преимущество.
Рассмотрим случаи, когда оконная функция полезна
Задача: получить поле, которое показывало бы, сколько всего было продано книг конкретного авторства, но без группировки по автору, как на картинках выше.
Для этого воспользуемся формулой:
Задача: получить поле, которое показывало бы, сколько всего было продано книг конкретного авторства, но без группировки по автору, как на картинках выше.
Для этого воспользуемся формулой:
sum(approximate_sales_in_millions) over (partition by author_s)
Новая для нас часть — over (partition by author_s). Она позволяет произвести агрегацию (в нашем случае — суммирование) не в целом всех значений, а разделяя по авторам.
Другой случай — итог с накоплением.
Попробуем проанализировать, как менялась динамика популярности автора с годами его публикаций. Для этого введем запрос, с помощью которого поле «накопление по автору» будет содержать не просто сумму от всех продаж, а только сумму продаж книг, написанных до определенного года.
Выглядеть это будет следующим образом:
Другой случай — итог с накоплением.
Попробуем проанализировать, как менялась динамика популярности автора с годами его публикаций. Для этого введем запрос, с помощью которого поле «накопление по автору» будет содержать не просто сумму от всех продаж, а только сумму продаж книг, написанных до определенного года.
Выглядеть это будет следующим образом:
sum(approximate_sales_in_millions) over (partition by author_s order by first_published)
1942 — 10 млн, 1947 — 10+12=22. Это и есть итог с накоплением. В оконной функции за такую функциональность будет отвечать параметр order by first_published
Предыдущие два пункта можно расширить, если использовать не только агрегирующую функцию суммирования, но и другие.
avg () — нахождение среднего
min () — минимум
max () — максимум
count () — подсчет количества
И это только небольшая часть других функций.
Выводы:
Предыдущие два пункта можно расширить, если использовать не только агрегирующую функцию суммирования, но и другие.
avg () — нахождение среднего
min () — минимум
max () — максимум
count () — подсчет количества
И это только небольшая часть других функций.
Выводы:
- Вычисляемые поля позволяют добавлять новые данные в таблицу, преобразуя данные из исходных полей.
- В вычисляемое поле можно записать математическое выражение или функцию, которая преобразует значение, хранящееся в поле.
- Оконные функции позволяют находить агрегаты данных, не меняя исходной структуры таблицы. Также только с их помощью можно добавить итоги с накоплением.