Настройка автоматического сбора статистики из Telegram
BI-системы позволяют компаниям собирать, анализировать и визуализировать данные для принятия обоснованных бизнес-решений. Такие системы могут собирать информацию из различных источников, так как обладают возможностью интеграции со сторонними сервисами через API.
Использование API для интеграции позволяет получать данные из таких источников, как CRM-системы, социальных сетей, веб-аналитика, платёжной системы и т. д. Это помогает компаниям создать полную картину о своей деятельности, клиентах и ситуации на рынке.
Поэтому в этот раз расскажем об интеграции AW BI с Telegram и как настроить автоматический сбор количества подписчиков из ТГ-сообщества.
В первую очередь нам нужно создать Telegram бота, зарегистрировать его и получить токен.
Использование API для интеграции позволяет получать данные из таких источников, как CRM-системы, социальных сетей, веб-аналитика, платёжной системы и т. д. Это помогает компаниям создать полную картину о своей деятельности, клиентах и ситуации на рынке.
Поэтому в этот раз расскажем об интеграции AW BI с Telegram и как настроить автоматический сбор количества подписчиков из ТГ-сообщества.
В первую очередь нам нужно создать Telegram бота, зарегистрировать его и получить токен.
Инструкция
- Отправьте в чат с BotFather команду: /newbot;
- Введите название бота — в этой категории особых ограничений нет;
- Введите юзернейм бота — его техническое имя, которое будет отображаться в адресной строке. К нему уже больше требований: юзернейм должен быть уникальным, написан на латинице и обязательно заканчиваться на bot. Так «Телеграм» защищается от злоумышленников, которые могут выдавать ботов за реальных людей;
- Готово. BotFather пришлёт токен бота — его можно использовать для настройки в сторонних сервисах.
После создания Telegram бота переходим к настройкам в Analytic Workspace.
Здесь нужно создать новую модель, добавить вычисляемую таблицу и определить в ней поля:
Здесь нужно создать новую модель, добавить вычисляемую таблицу и определить в ней поля:
- date — тип «Дата»;
- members_count — тип «Число»;
- tg_group_name — тип «Строка».
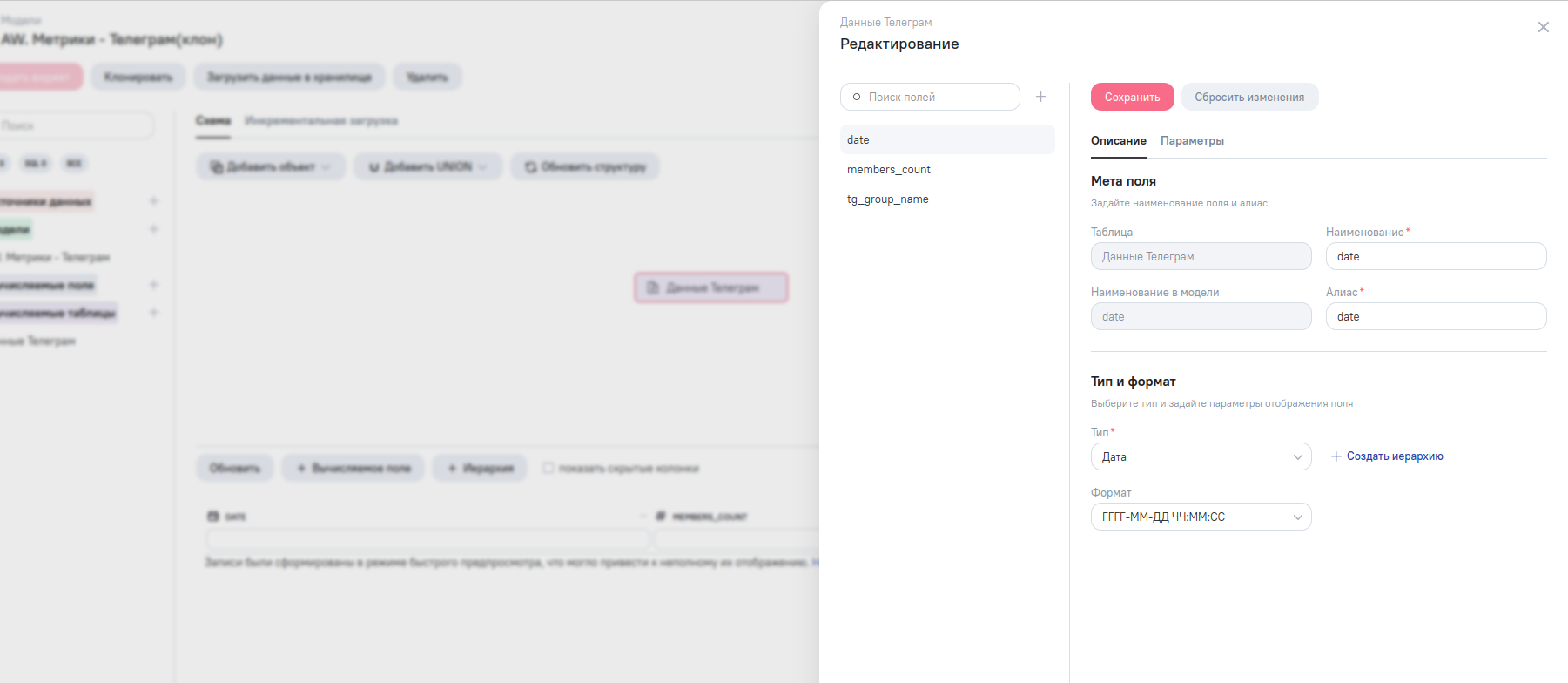
Таблицу отправляем на схему модели и переходим в ETL-редактор. Затем запускаем код:
import requests
from pyspark.sql import Row
import json
from datetime import datetime
def after_all(df, spark, app, *args, **kwargs):
# variables for telegram api
# input yours
bot_token = '64:AAEet'
chat_ids = ["@awcommunity", "@awbi_ru"]
def get_chat_name(chat_id):
try:
path = f'https://api.telegram.org/bot{bot_token}/getChat?chat_id={chat_id}'
response = requests.get(path)
if not response.ok:
raise Exception(f'\nОшибка URL: {response.url} \/n {response.status_code}: {response.text}')
return response.json()
except Exception as e:
print(e)
def get_chat_member_count(chat_id):
try:
path = f'https://api.telegram.org/bot{bot_token}/getChatMemberCount?chat_id={chat_id}'
response = requests.get(path)
if not response.ok:
raise Exception(f'\nОшибка URL: {response.url} \/n {response.status_code}: {response.text}')
return response.json()
except Exception as e:
print(e)
def get_community_stat(chat_id):
res = get_chat_member_count(chat_id)
member_count = None
if res:
member_count = res["result"]
now = datetime.now()
return [now, member_count]
def get_telegram_chat_title(chat_id):
res = get_chat_name(chat_id)
telegram_chat_title = None
if res:
telegram_chat_title = res["result"]["title"]
return telegram_chat_title
result_rows = []
for chat_id in chat_ids:
[current_date, members_count] = get_community_stat(chat_id)
telegram_chat_title = get_telegram_chat_title(chat_id)
result_row = [current_date, members_count, telegram_chat_title]
result_rows.append(result_row)
print(result_rows)
df = df.union(spark.createDataFrame(result_rows))
return dfВажно! В переменной bot_token необходимо указать токен Telegram бота, а в chat_ids перечислить username каналов и групп, по которым нужно собирать статистику.
И, конечно, сохраните скрипт.
Далее перейдём к настройке периодической подгрузки данных. Для этого необходимо выполнить следующие шаги:
Затем фрагменты вычисляемой таблицы и модели необходимо добавить в блок UNION.
И, конечно, сохраните скрипт.
Далее перейдём к настройке периодической подгрузки данных. Для этого необходимо выполнить следующие шаги:
- Первичная загрузка. На схему модели добавлена только вычисляемая таблица. Запускаем синхронизацию и дожидаемся успешного выполнения;
- Теперь необходимо добавить на схему:
- новый блок UNION;
- фрагмент той же самой модели, в которой сейчас ведётся настройка.
Затем фрагменты вычисляемой таблицы и модели необходимо добавить в блок UNION.
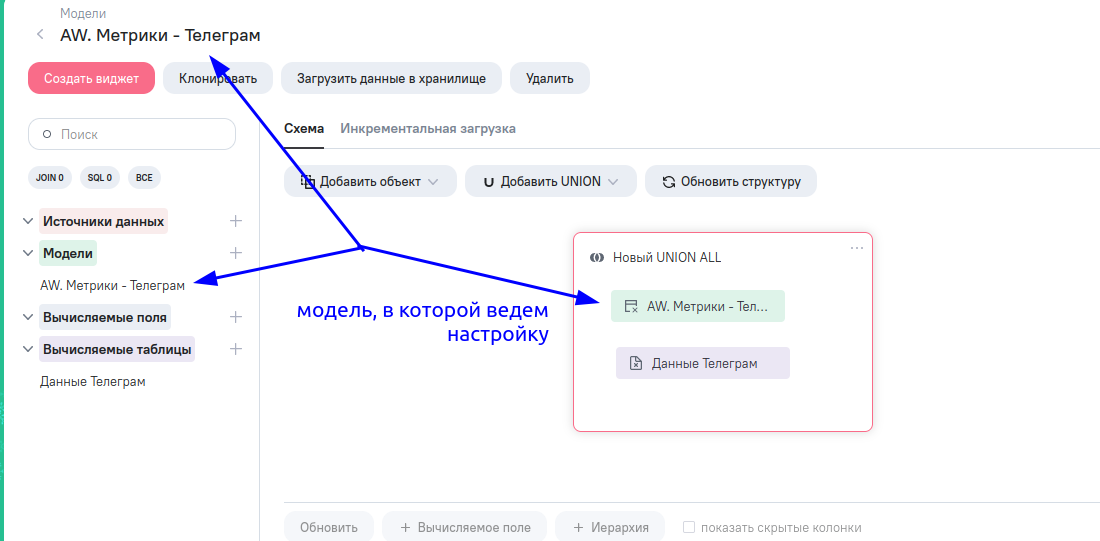
Таким образом, при каждой загрузке, вычисляемая таблица будет забирать статистику сообществ на текущую дату, а в самой модели будет накопительная статистика за прошлые периоды. При запуске синхронизации это данные будут объединяться в одну таблицу.
Также можно настроить запуск синхронизаций по расписанию (раздел «Планировщик» в настройках модели).
Эти данные можно визуализировать и отслеживать динамику роста групп.
Также можно настроить запуск синхронизаций по расписанию (раздел «Планировщик» в настройках модели).
Эти данные можно визуализировать и отслеживать динамику роста групп.